Надо обратить внимание на один важный момент в реализации функции поиска идентификатора в дереве (function TVarInfo.FindElCnt). Если выполнять сравнение двух строк (в данном случае – имени искомого идентификатора sN и имени идентификатора в текущем узле дерева sName) с помощью стандартных методов сравнения строк языка Object Pascal, то фрагмент программного кода выглядел бы примерно так:
if sN < sName then
begin
…
end
else
if sN > sName then
begin
…
end
else…
В этом фрагменте сравнение строк выполняется дважды: сначала проверяется отношение "меньше" (sN < sName), а потом – "больше" (sN > sName). И хотя в программном коде явно это не указано, для каждого из этих операторов будет вызвана библиотечная функция сравнения строк (то есть операция сравнения может выполниться дважды!). Чтобы этого избежать, в реализации предложенной в примере выполняется явный вызов функции сравнения строк, а потом обрабатывается полученный результат:
i:= StrComp(PChar(sN), PChar(sName));
if i < 0 then
begin
…
end
else
if i > 0 then
begin
…
end
else…
В таком варианте дважды может быть выполнено только сравнение целого числа с нулем, а сравнение строк всегда выполняется только один раз, что существенно увеличивает эффективность процедуры поиска.
Организация таблиц идентификаторов
Таблицы идентификаторов реализованы в виде статических массивов размером HASH_MIN..HASH_MAX, элементами которых являются структуры данных типа TVarInfo. В языке Object Pascal, как было сказано выше, для структур таких типов хранятся ссылки. Поэтому для обозначения пустых ячеек в таблицах идентификаторов будет использоваться пустая ссылка – nil.
Поскольку в памяти хранятся ссылки, описанные массивы будут играть роль хэш-таблиц, ссылки из которых указывают непосредственно на информацию в таблицах идентификаторов.
На рис. 1.3 показаны условные схемы, наглядно иллюстрирующие организацию таблиц идентификаторов. Схема 1 иллюстрирует таблицу идентификаторов с рехэшированием на основе генератора псевдослучайных чисел, схема 2 – таблицу идентификаторов на основе комбинации хэш-адресации с бинарным деревом. Ячейки с надписью "nil" соответствуют незаполненным ячейкам хэш-таблицы.
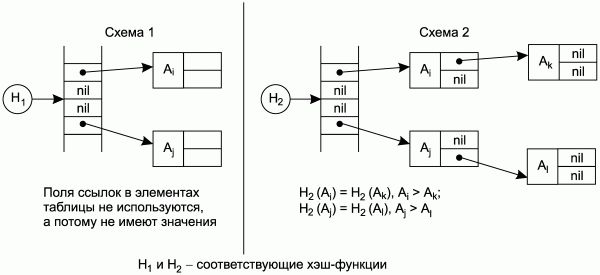
Рис. 1.3. Схемы организации таблиц идентификаторов.
Для каждой таблицы идентификаторов реализованы следующие функции:
• функции начальной инициализации хэш-таблицы – InitTreeVar и InitHashVar;
• функции освобождения памяти хэш-таблицы – ClearTreeVar и ClearHashVar;
• функции удаления дополнительной информации в таблице – ClearTreeInfo и ClearHashInfo;
• функции добавления элемента в таблицу идентификаторов – AddTreeVar и AddHashVar;
• функции поиска элемента в таблице идентификаторов – GetTreeVar и GetHashVar;
• функции, возвращающие количество выполненных операций сравнения при размещении или поиске элемента в таблице – GetTreeCount и GetHashCount.
Алгоритмы поиска и размещения идентификаторов для двух данных методов организации таблиц были описаны выше в разделе "Краткие теоретические сведения", поэтому приводить их здесь повторно нет смысла. Они реализованы в виде четырех перечисленных выше функций (AddTreeVar и AddHashVar – для размещения элемента; GetTreeVar и GetHashVar – для поиска элемента). Функции поиска и размещения элементов в таблице в качестве результата возвращают ссылку на элемент таблицы (структура которого описана в модуле TblElem) в случае успешного выполнения и нулевую ссылку – в противном случае.
Надо отметить, что функции размещения идентификатора в таблице организованы таким образом, что если на момент помещения нового идентификатора в таблице уже есть идентификатор с таким же именем, то функция не добавляет новый идентификатор в таблицу, а возвращает в качестве результата ссылку на ранее помещенный в таблицу идентификатор. Таким образом, в таблице не может быть двух и более идентификаторов с одинаковым именем. При этом наличие одинаковых идентификаторов во входном файле не воспринимается как ошибка – это допустимо, так как в задании не предусмотрено ограничение на наличие совпадающих имен идентификаторов.
Все перечисленные функции описаны в двух программных модулях: FncHash – для таблицы идентификаторов, построенной на основе рехэширования с использованием генератора псевдослучайных чисел, и FncTree – для таблицы идентификаторов, построенной на основе комбинации хэш-адресации и бинарного дерева. Кроме массивов данных для организации таблиц идентификаторов и функций работы с ними эти модули содержат также описание переменных, используемых для подсчета количества выполненных операций сравнения при размещении и поиске идентификатора в таблицах.
Полные тексты обоих модулей (FncHash и FncTree) можно найти на веб-сайте издательства, в файлах FncHash.pas и FncTree.pas. Кроме того, текст модуля FncTree приведен в листинге П3.2 в приложении 3.
Хочется обратить внимание на то, что в разделах инициализации (initialization) обоих модулей вызывается функция начального заполнения таблицы идентификаторов, а в разделах завершения (finalization) обоих модулей – функция освобождения памяти. Это гарантирует корректную работу модулей при любом порядке вызова остальных функций, поскольку Object Pascal сам обеспечивает своевременный вызов программного кода в разделах инициализации и завершения модулей.
Текст программы
Кроме перечисленных выше модулей необходим еще модуль, обеспечивающий интерфейс с пользователем. Этот модуль (FormLab1) реализует графическое окно TLab1Form на основе класса TForm библиотеки VCL. Он обеспечивает интерфейс средствами Graphical User Interface (GUI) в ОС типа Windows на основе стандартных органов управления из системных библиотек данной ОС. Кроме программного кода (файл FormLab1.pas) модуль включает в себя описание ресурсов пользовательского интерфейса (файл FormLab1.dfm). Более подробно принципы организации пользовательского интерфейса на основе GUI и работа систем программирования с ресурсами интерфейса описаны в [3, 5, 6, 7].
Кроме описания интерфейсной формы и ее органов управления модуль FormLab1 содержит три переменные (iCountNum, iCountHash, iCountTree), служащие для накопления статистических результатов по мере выполнения размещения и поиска идентификаторов в таблицах, а также функцию (procedure ViewStatistic) для отображения накопленной статистической информации на экране.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
• многострочное поле для отображения прочитанного файла (Listldents);
• поле ввода имени искомого идентификатора (EditSearch);
• кнопка для поиска введенного идентификатора (BtnSearch) – этой кнопкой однократно вызывается процедура поиска (procedure SearchStr);
• кнопка автоматического поиска всех идентификаторов (BtnAllSearch) – этой кнопкой процедура поиска идентификатора (procedure SearchStr) вызывается циклически для всех считанных из файла идентификаторов (для всех, перечисленных в поле Listldents);
• кнопка сброса накопленной статистической информации (BtnReset);
• поля для отображения статистической информации;
• кнопка завершения работы с программой (BtnExit).
Внешний вид этой формы приведен на рис. 1.4.